終於我們歷經千辛萬苦的了解了 Grafana LGTM 全家桶的大部分的核心成員,從 Loki、Grafana 到 Tempo 現在我們終於要進入可以說是最關鍵的 Grafana Mimir 實戰篇了,雖然是 Grafana Mimir 使用起來就像 Prometheus 沒兩樣,但別忘記了他真正的存在的意義,是作為Prometheus的可擴展長期存儲解決方案,且它擁有比 Tempo、Loki 更悠久的歷史淵源,可想而知,Grafana Mimir 的設定是肯定是最為複雜,不過我們都走到這麼遠了,肯定不能在這裡停下,接下來就讓我們實際體驗它的強大吧。

就像是先前提到的 Loki 及 Tempo 一樣,Grafana Mimir 也依照顆粒出戲,為我們提供了以下三種部署模式:
讀寫模式目前仍處於實驗階段,僅支援 Jsonnet 方式安裝。
單體模式是 Grafana Mimir 中最簡單的操作設定,開箱及用,對第一次體驗的人非常友善。單體模式可以讓我們在單一進程、一個二進制檔、一個 Docker Image 中,運作起包含所有微服務組件。
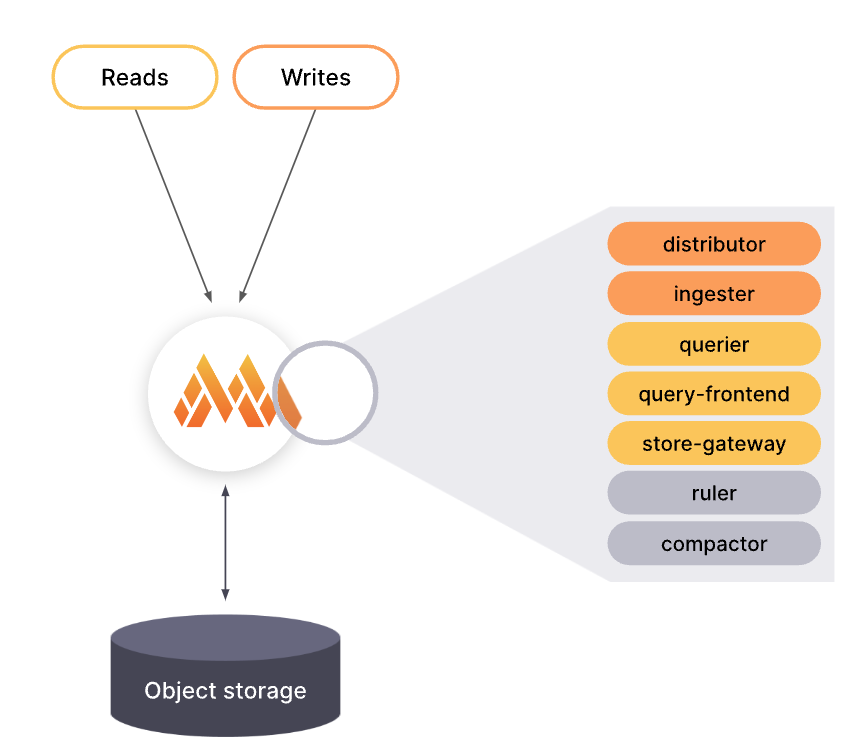
單體模式也支援水平擴展,唯一不同的是他需要在水平擴展的服務前,建立一個負載均衡器來分配流量。這個方式提供了高可用性及高負載能力,卻不用面對到微服務模式的配置複雜度。
微服務模式下的 Grafana Mimir 擁有最大的彈性以及最細的控制顆粒程度,這是目前 Grafana Labs 對 Mimir 推薦的首選模式,不同於 Loki 推薦的讀寫模式。雖然使用微服務模式最為複雜,但同時也能達到最佳的調教效率。
每個組件部署關聯配置必須指定 target 為特定組件,像是 -target=querier,且必須為滿足 Mimir 最低所需的每種組件才能順利執行。
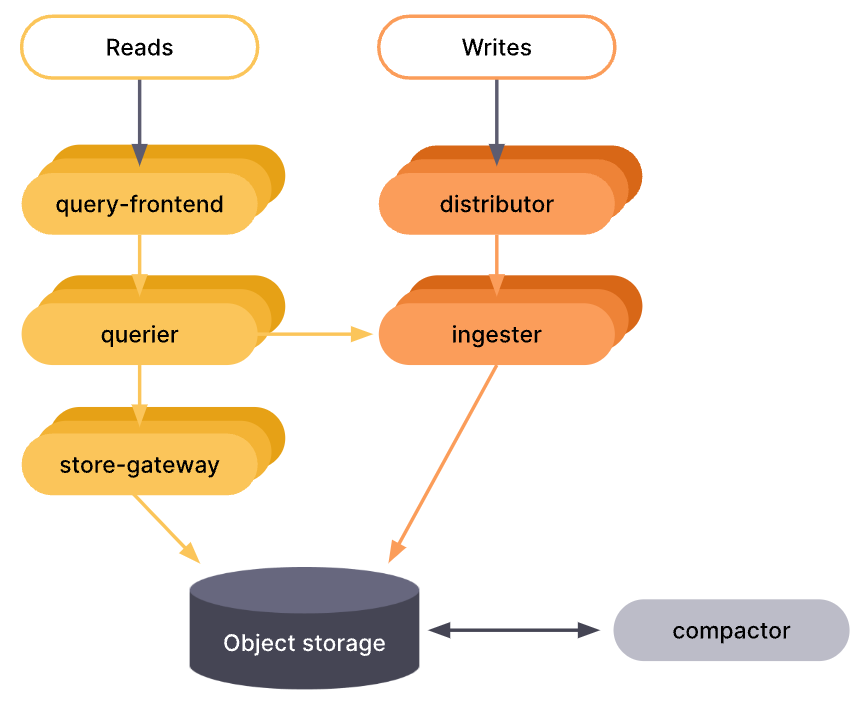
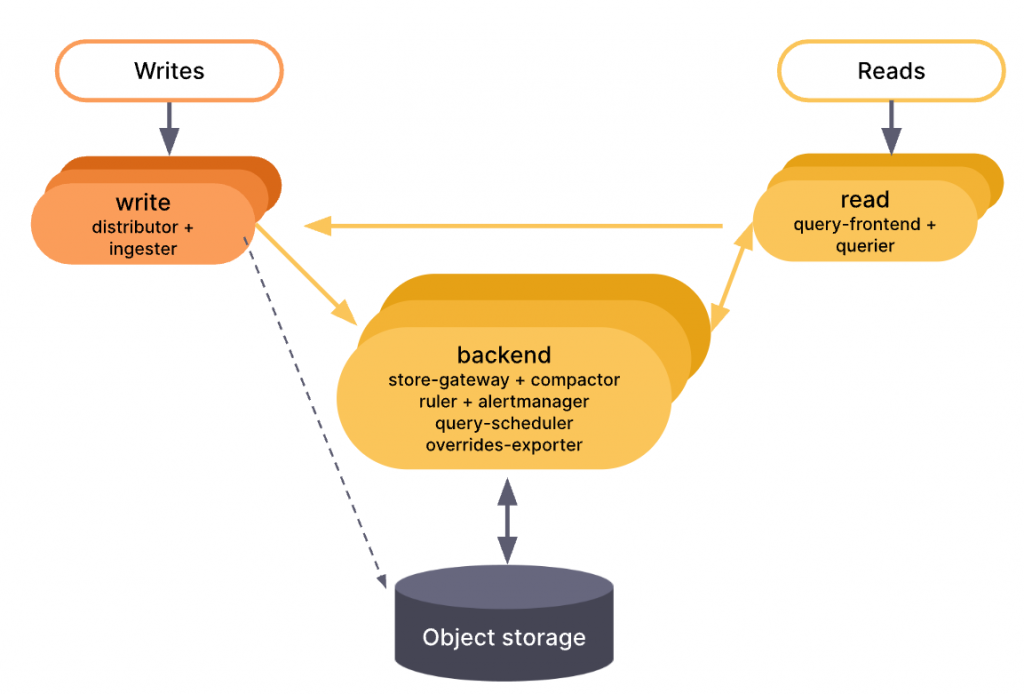
讀寫模式提供了介於單體與微服務模式之間的替代方案。
在讀寫模式下,所有組件被分為三個大模組,以減輕配置的複雜程度,但同時也允許我們為不同模組分別擴展,依照實際需求單獨調整模組規模。
這些模組將組件分組如下:
helm search repo mimir | grep grafana/mimir
------
grafana/mimir-distributed 5.1.0 2.10.0 Grafana Mimir
grafana/mimir-openshift-experimental 2.1.0 2.0.0 Grafana Mimir on OpenShift Experiment
在 Helm Chart 的選擇上,Grafana Labs 目前只有提供 mimir-distributed 微服務模式的版本,而 mimir-openshift-experimental 則是為了在 Red Head Openshift 平台上運作的客製版本,所以這裡我們理所當然的選擇我們已經熟悉的 mimir-distributed 微服務版本作為實戰項目。
在接下來的實戰中,我們將利用先前建立好的 Kube-Prometheus-Stack 及其相關設定來當作 Grafana Mimir 的可視化介面,其中詳細安裝過程可以回頭複習一下「Kube-Prometheus-Stack 實戰系列」,並且有趣的是我們還會繼續利用「Grafana Tempo 實戰系列」所安裝的 Tempo 服務當作存儲 Grafana Mimir 的追蹤信號。
不同的是我們將解開 Prometheus 進階功能的封印:
# values.yaml
....
prometheus:
enabled: true
prometheusSpec:
enableFeatures:
- exemplar-storage
enableRemoteWriteReceiver: true
remoteWriteDashboards: true
remoteWrite:
- url: http://mimir-gateway.monitoring/api/v1/push
我們只將原先的設定檔 enableRemoteWriteReceiver 參數調成 true,並且將 enbleFeatures 中添加 exemplar-storage 存儲功能,再加上遠端寫入的目的地指向到 Grafana Mimir,即可馬上執行 helm 更新。
注意:如果沒有開啟 exemplar-storage 但遠程寫入 Exemplar 時,在 Prometheus 中只能看到監控指標,而不是監控指標加追蹤資訊的 Exemplar。
helm upgrade --install prometheus-stack prometheus-community/kube-prometheus-stack --values=values.yaml -n prometheus --create-namespace
現在我們要使用 values.yaml 兩個參數檔,進行對 Grafana Mimir 的設定。
# values.yaml
fullnameOverride: mimir
global:
extraEnv:
- name: JAEGER_AGENT_HOST
value: tempo-distributor.tracing
- name: JAEGER_SAMPLER_PARAM
value: "1"
mimir:
structuredConfig: {}
runtimeConfig: {}
distributor:
replicas: 1
ingester:
replicas: 3
statefulSet:
enabled: true
persistentVolume:
enabled: true
zoneAwareReplication:
enabled: false
querier:
replicas: 2
query_frontend:
replicas: 1
query_scheduler:
enabled: true
replicas: 2
store_gateway:
replicas: 1
zoneAwareReplication:
enabled: false
compactor:
replicas: 1
memcachedExporter:
enabled: false
chunks-cache:
enabled: false
replicas: 1
index-cache:
enabled: false
replicas: 1
metadata-cache:
enabled: false
replicas: 1
results-cache:
enabled: false
replicas: 1
rollout_operator:
enabled: true
minio:
enabled: true
nginx:
enabled: false
gateway:
enabledNonEnterprise: true
replicas: 1
autoscaling:
enabled: false
alertmanager:
enabled: true
zoneAwareReplication:
enabled: false
overrides_exporter:
enabled: true
replicas: 1
ruler:
enabled: true
replicas: 1
metaMonitoring:
dashboards:
enabled: true
serviceMonitor:
enabled: ture
prometheusRule:
enabled: true
grafanaAgent:
enabled: false
values.yaml 主要針對所有組件在 Kubernetes 叢集中的相關資源設定。
helm upgrade --install mimir grafana/mimir-distributed -f values.yaml -n monitoring --create-namespace
----
Release "mimir" does not exist. Installing it now.
W1004 23:12:06.731248 83119 warnings.go:70] metadata.name: this is used in Pod names and hostnames, which can result in surprising behavior; a DNS label is recommended: [must not contain dots]
NAME: mimir
LAST DEPLOYED: Wed Oct 4 23:12:02 2023
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
Welcome to Grafana Mimir!
Remote write endpoints for Prometheus or Grafana Agent:
Ingress is not enabled, see the gateway.ingress values.
From inside the cluster:
http://mimir-gateway.monitoring.svc:80/api/v1/push
Read address, Grafana data source (Prometheus) URL:
Ingress is not enabled, see the gateway.ingress values.
From inside the cluster:
http://mimir-gateway.monitoring.svc:80/prometheus
**IMPORTANT**: Always consult CHANGELOG.md file at https://github.com/grafana/mimir/blob/main/operations/helm/charts/mimir-distributed/CHANGELOG.md and the deprecation list there to learn about breaking changes that require action during upgrade.
接下來我們就可以在 Kubernetes 叢集中看到熟悉各種 Mimir 組件:
kubectl get pods -n monitoring
---
NAME READY STATUS RESTARTS AGE
mimir-alertmanager-0 1/1 Running 0 24h
mimir-compactor-0 1/1 Running 0 24h
mimir-distributor-bc8499b4-tsnbc 1/1 Running 0 24h
mimir-gateway-cbbc7c65b-5d6sj 1/1 Running 1 (14h ago) 24h
mimir-ingester-0 1/1 Running 0 24h
mimir-ingester-1 1/1 Running 0 24h
mimir-ingester-2 1/1 Running 0 24h
mimir-make-minio-buckets-5.0.7-h52lj 0/1 Completed 0 25h
mimir-minio-7f48b8f875-rvzhw 1/1 Running 1 (25h ago) 25h
mimir-overrides-exporter-85b4b64f5d-z7cb7 1/1 Running 0 24h
mimir-querier-84b79f8d-2rkq5 1/1 Running 0 24h
mimir-querier-84b79f8d-kqnk8 1/1 Running 0 24h
mimir-query-frontend-79f98b85d8-pnvmj 1/1 Running 0 24h
mimir-query-scheduler-5f8f7f989-fc88x 1/1 Running 0 24h
mimir-query-scheduler-5f8f7f989-j6l59 1/1 Running 0 24h
mimir-rollout-operator-585f467754-78nvx 1/1 Running 1 (25h ago) 25h
mimir-ruler-cdf6bfff9-9j5wj 1/1 Running 0 24h
mimir-store-gateway-0 1/1 Running 0 24h
現在我們已經成功運作起來完整的微服務模式 Grafana Mimir。操作到這裡的我們已經成功了一半,接下來我們可以用我們原先建立好的 Prometheus 模擬一個不同叢集的監控指標集中到 Grafana Mimir 上的情況。
注意:請記住,啟用遠端寫入後,Prometheus 記憶體使用量可能增加至兩倍使用量。
以下將詳細拆解我們使用到的參數設定檔,幫助大家了解實際設定。
metaMonitoring:
dashboards:
enabled: true
serviceMonitor:
enabled: ture
prometheusRule:
enabled: true
grafanaAgent:
enabled: false
prometheusRule:
enabled: true
幫助我們預先建立 Grafana Tempo 的 serviceMonitor 以及 prometheusRule,提供開箱及用的 Prometheus 指標設定和告警,Grafana Mimir 也預設提供多種生產環境中幫助維運的 Grafana 儀表板。
global:
extraEnv:
- name: JAEGER_AGENT_HOST
value: tempo-distributor.tracing
- name: JAEGER_SAMPLER_PARAM
value: "1"
Grafana Mimir 使用 Jaeger 來實現分佈式追蹤,用於對生產中 Grafana Mimir 的行為進行故障排除。這裡我們將 JAEGER_AGENT_HOST 指向我們先前建立好的 Tempo,並且設定 Sample Rate 為百分之百。
有趣的是 Grafana Mimir 目前依然繼續使用從 Cortex 時代使用的 Jaeger 當作分佈式追蹤,而不是自家力推的 Opentelemetry 不過我們也可以觀察未來 Grafana 是否也會將這個部分一起改掉。
mimir:
structuredConfig: {}
runtimeConfig: {}
ingester:
zoneAwareReplication:
enabled: false
alertmanager:
zoneAwareReplication:
enabled: false
store_gateway:
zoneAwareReplication:
enabled: false
rollout_operator:
enabled: false
Grafana Mimir 可以依據設定來指定服務部署在不同的區域,來大幅降低單一可用區域失敗的風險。
而 rollout_operator 是一個 Kubernetes Operator,專門用於協調特定命名空間內不同 StatefulSets 間的 pods 的滾動更新,特別適用於管理多可用區域部署。
根據 Grafana Mimir 部署的底層基礎設施,區域可以是:
注意:不同的可用區可能會帶來額外的跨可用區費用,如有需要可以調整壓縮編碼 snappy 到 gzip 提高壓縮效率。
minio:
enabled: true
Grafana Mimir distributed Helm Chart 預設物件存儲後段為 S3,而如果使用其他物件存儲後端如 GCS 則需要手動修改設定。為了在本地測試方便,Grafana 提供了 minio 服務,可以實現所有 S3 物件操作介面,使 Mimir 在實際運作時,可以輕易的使用 S3 任何接口。
memcachedExporter:
enabled: false
chunks-cache:
enabled: false
replicas: 1
index-cache:
enabled: false
replicas: 1
metadata-cache:
enabled: false
replicas: 1
results-cache:
enabled: false
replicas: 1
這裡我們可以視需求開啟 MemCached 組件,增加查詢效率,並且 Mimir 也很貼心地替我們準備好 MemCached Exporter 提供我們監控指標。
compactor:
replicas: 1
這邊需要注意的是 Grafana Mimir distributed 中的跟 Loki 不能直接設定 Retention 時間,但 Mimir 的 Compactor 預設 Retention 設定是 disable 的,也就是沒有特地設定的話他將會永遠保留數據。
# mimir-config
limit:
compactor_blocks_retention_period: <duration> | default = 0s
nginx:
enabled: false
gateway:
enabledNonEnterprise: true
replicas: 1
autoscaling:
enabled: false
目前 Nginx 組件已經被 Gateway 組件淘汰掉了,所以我們必須確保兩者沒有同時開啟。Gateway 是一個同樣以 Nginx 服務在 Grafana Mimir 組件最前方替我們負載均衡所有讀寫請求的守門人,並且提供基本的驗證,相關設定都在此處調整,可以大大降低我們將 Mimir 端點公開的風險。
alertmanager:
enabled: true
overrides_exporter:
enabled: true
replicas: 1
ruler:
enabled: true
replicas: 1
Mimir 提供一些可選組件,其中比較特別的是當開啟 overrides_exporter 時,每個租戶的相關設定將會以監控指標的形式曝露出來,這樣我們就可以 Grafana 儀表板上顯示個別租戶的設定狀態。
首先讓我們將 Grafana 端點導出來:
kubectl port-forward service/prometheus-stack-grafana 3000:80 -n prometheus
------
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
接著進入我們本機中的 localhost:3000 就能看到精美的 Grafana Login 頁面。
現在我們就在 Data Sources 中將我們的 mimir-gateway 或 mimir-query-frontend 查詢組件的端點新增到 Grafana 上。
在我們進入 Explore 選擇 Mimir 為數據源後,我們可以很快的看到 Metrics Explorer 中已經充滿了各式監控指標,這代表我們唯一的資料來源 Prometheus 已經成功的寫入資料進來。
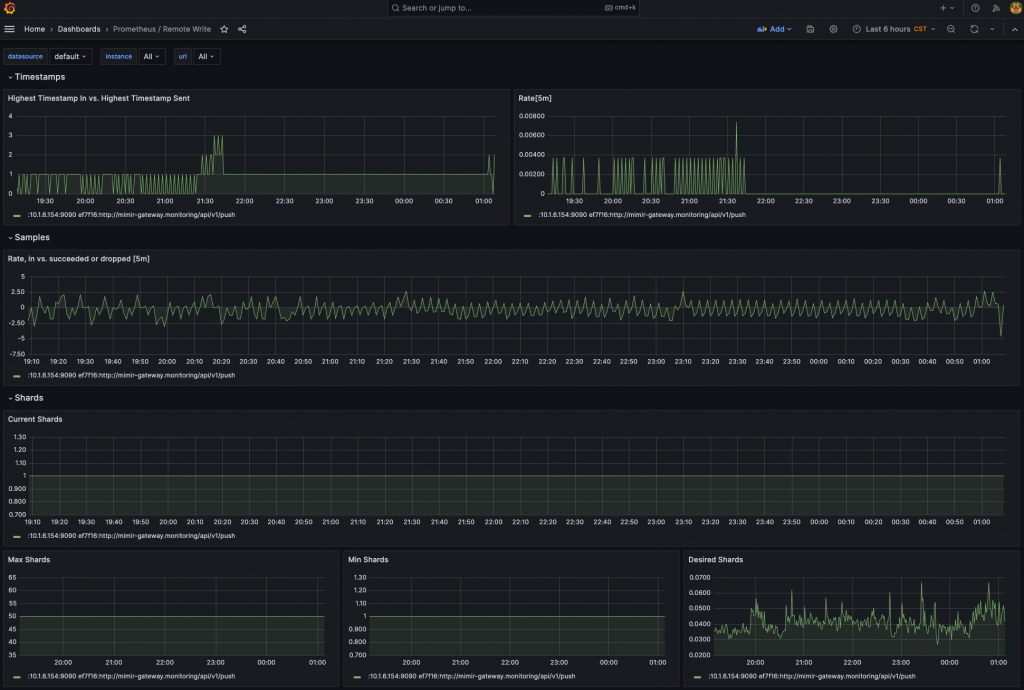
這時我們在一開始開啟的 Prometheus 遠端寫入功能就派上用場了,我們可以打開一起被注入的 RemoteWrite 儀表板確認運作情況。
還記得我們在不久前特地將 Mimir 中的 Jaeger 追蹤信號存入我們預先建立好的 Tempo 嗎?現在就讓我們來實際看看,Mimir 的追蹤資料是否成功寫入,並且能為我們帶來什麼樣的資訊。
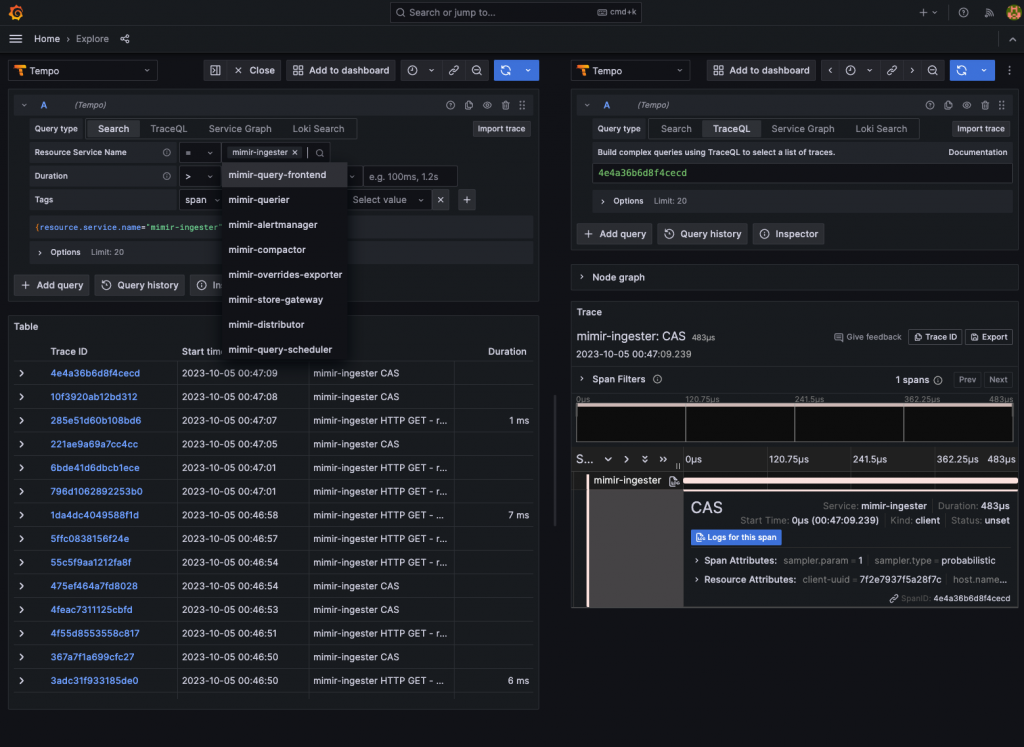
舉例來說,這裡我們可以清楚的看到因為 Ingestor 組件預設的複製因子為 3,所以 Distributor 組件將會發送同樣的請求給 3 個不同的 Ingestor 寫入,實現資料冗餘來降低資料遺失的風險,但講歸講,如果沒有分佈式追蹤的可視化介面輔助,我們在平常開發維護時是根本無從驗證是否真的傳了 3 次同樣的請求給 3 個 Ingestor,但我們現在有個 Mimir 準備好的追蹤信號,讓整個資料冗餘的過程都一目瞭然!
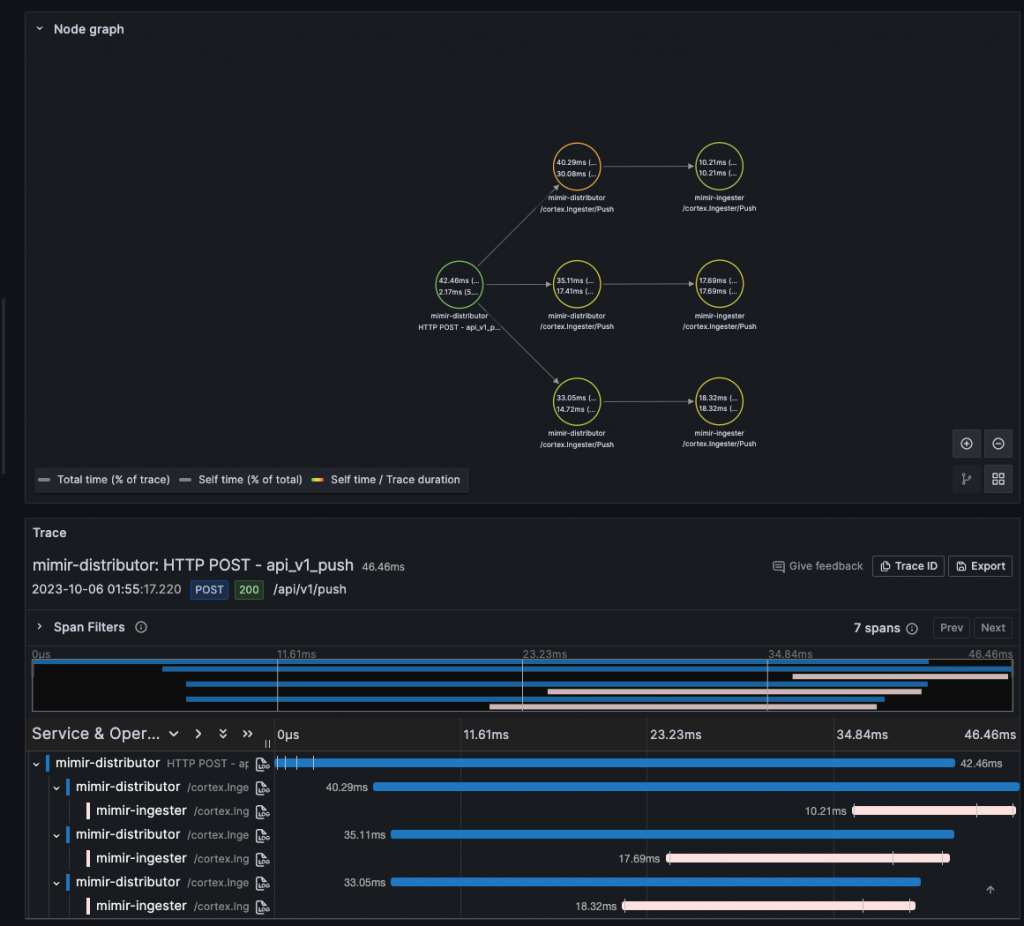
本篇為「Grafana LGTM 全家桶系列文」的最終實戰章節,感謝一路陪伴到最後的讀者們。Grafana Mimir 無疑是一個能夠承載極大數量時序資料的強大資料庫。在多數的企業或工作場景中,我們鮮少需要保存數月或數年的監控數據,通常僅需維持一到兩周或是一個月的資料。即使是在本地環境中,Mimir 所需的資源也相對龐大。以我的 16G M1 Mac 運行 Mimir 為例,都能感受到其運算負擔。然而,從學習 Grafana Mimir 的過程中,我們可以反覆品味 Grafana Labs 的架構理念,間接加深我們對 Tempo、Loki、和 Prometheus 的認識,進一步邁向可觀測性宇宙。
相關程式碼同步收錄在:
https://github.com/MikeHsu0618/grafana-stack-in-kubernetes/tree/main/day29
References
Configure Grafana Mimir high-availability deduplication | Grafana Mimir documentation
Configure Grafana Mimir metrics storage retention | Grafana Mimir documentation
Configure Grafana Mimir tracing | Grafana Mimir documentation
請問 Tempo如果有設定 multitenancy_enabled的話,Mimir那邊的extraEnv該怎麼加入tenant ID 給 Tempo,我看到tempo-query-frontend跟
tempo-distributor pod裡面的log一直出現:
2024-03-14T11:27:46+08:00 ts=2024-03-14T03:27:46.638144925Z caller=middleware.go:68 msg="failed to extract org id from both grpc and HTTP" err="no org id" client=unknown
2024-03-14T11:27:46+08:00 ts=2024-03-14T03:27:46Z level=error msg="Processor failed" component=tempo error="no org id"
就我個人的理解,此功能比較偏向本地端 debug 作用,不算是一個feature,所以在 source code 中沒有特別開放客製 request header 的設定。
如果真的需要 tracing 資料,就必須再多經過一層 otel collector 或 grafana agant 的角色去額外附加資訊上去。
以上純屬個人看法,歡迎指正~
感謝,我目前的做法是先把multitenancyEnabled設成false了


 iThome鐵人賽
iThome鐵人賽